2018-2019-1 20165202 《信息安全系统设计基础》第六周学习总结
教材学习内容总结
输入/输出(I/O)是在主存和外部设备之间复制数据的过程。输入操作是从I/O设备复制数据到主存,输出操作是从主存复制数据到I/O设备。
在Unix系统中,通过使用由内核提供的系统级UnixI/O函数来实现较高级别的I/O函数。但是Unix I/O的学习也必不可少,Unix I/O是系统操作不可或缺的部分,我们需要通过学习理解其他的系统概念,而且很多时候,使用高级I/O函数不太合适,还是需要使用Unix I/O。而且这一章是网络编程和并发性的前提和基础,所以我决定重新学习一下。
1 Unix I/O
具体Unix I/O是什么呢?
一个Unix文件就是一个m个字节的序列,所有I/O设备(例如网络、磁盘和终端)都被模型化为文件,所有输入和输出都被当作对相应文件的读和写来执行。这种将设备优雅的映射为文件的方式,允许Linux内核引出一个简单、低级的应用接口,简称Unix I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行:
先了解一个概念,叫做描述符:描述符是内核返回的、一个较小的非负整数,它记录着有关这个文件的信息,应用程序无需记住这个文件在哪里、什么格式、多大,只需要记住这个描述符,就可以对这个文件进行相应的操作。
打开文件。一个应用程序通过要求内核打开相应的文件,来告诉它想要访问的
I/O设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文间的所有操作中标识这个文件。内核记录有关这个打开文件的所有信息。应用程序只需要记住这个描述符。- Unix shell 创建的每个进程开始时都由三个打开的文件:标准输入(描述符为0)、标准输出(描述符为1)和标准错误(描述符为2)。
改变当前的文件位置。对于每个打开文件,内核保持着一个文件位置k,初始为0。即从文件开头起始的字节编偏移量。
- 读写文件。
- 一个读操作就是从文件复制
n>0个字节到内存,从当前文件位置k开始,然后将k增加到k+n。当超过文件字节大小时,读操作会出发一个end-of-file的条件,应用程序能检测到这个条件。 - 同理,写操作就时从内存复制n个字节到一个文件中。
- 一个读操作就是从文件复制
关闭文件。当应用完成对文件的访问之后,它就通知内核关闭文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述父回复到可用的描述符池中。无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放他们的内存资源。
2 打开和关闭文件
进程通过open函数来打开一个已存在的文件或者创建一个新文件的:
#include#include #include int open(char *filename, int flags, mode_t mode); //返回值:若成功则为文件描述符,出错为-1。
- 该函数将
filename转换为一个文件描述符,并且返回描述符数字。 flags指明如何访问这个文件:O_RDONLY(只读),O_WRONLY(只写),O_RDWR(读写)flags还有为写操作提供一些额外指示的掩码,在使用时把他们或起来就好。O_CREAT:如果文件不存在,那就创建它的一个截断的空文件。O_TRUNC如果文件已存在,就截断它。O_APPEND在每次写操作前,设置文件位置到文件的结尾处。(学习Java的时候,append就可以向String后面添加String)
- 而
mode制定了新文件的访问权限位,在sys/stat.h头文件中定义,我们可以使用#define来将多种权限复合在一起,省略重复写这么多字母。 
先复习下之前讲用户对文件的权限:权限分三种:(r)可读、(w)可写、(x)可执行对用户的限制分三种:User(当前用户)、Groups(用户所在组的成员)、Every one(所有人)
巧妙使用#define
#define MY_MODE S_IRUSR|SIWUSR|S_IXUSR#define GROUP_MODE S_IRGRP|S_IWGRP|S_IXGRP
当我们打开一个存在的文件,mode_t mode定义为0即可。
int fd=open("foo.txt",O_WRONLY,0); 想要在一个已存在文件后面添加一些数据:
int fd=open("foo.txt",O_WRONLY|O_APPEND,0); 想要创建一个新文件:
int fd=open("foo.txt",O_WRONLY|O_CREAT|O_TRUNC,MY_MODE);//这行代码代表,创建一个新文件(如果已存在,截断它!)User有读写和可执行权限 打开一个文件后,一定要记得关闭!
#includeint close(int fd);
10.3 读和写文件
应用程序都是通过调用read和write函数来执行输入和输出的。
#includessize_t read(int fd, void *buf, size_t n);//若成功则返回读到的字节数,EOF则返回0,出错为-1。
read函数从描述符为fd的当前文件位置拷贝最多n个字节到buf。
#includessize_t write(int fd, const void *buf, size_t n);
write函数从buf拷贝最多n个字节到fd的当前文件位置。- 某些情况的时候,
read和write传送的字节比应用程序要求的要少,这些“不足”并不代表错误。出现这种情况的原因有以下几个:- 读时遇到
EOF:假设该文件从要求位置开始只有20字节,而函数要求50字节的片进行读取,这样就会导致read的返回值为20,此后的read将通过返回不足值0来发出EOF信号。 - 从终端读文本行。如果打开文件是与终端关联(如键盘和显示器),那么每个
read函数将一次传送一个文本行返回的不足值等于问本行的大小。 - 读和写网络套接字。如果打开的文件对应网络套接字,那么内部缓冲约束和较长的网络延迟会引起
read和write返回不足值。 - 对
Unix 管道(pipe)调用read和write时,也有可能出现不足值。
- 读时遇到
除了EOF,在读写磁盘文件的时候,不会遇到不足值。
read和write处理不足值,直到所有字节都传送完毕。 4 用RIO包健壮地读写
Robust I/O包(RIO 包)会自动处理不足值。在像网络程序这样容易出现不足值的引用中,RIO包提供了方便、健壮和高效的I/O。
RIO主要是因为,在开发网络应用中使用了RIO包,并且通过学习后对Unix I/O会有更深入的了解。 RIO提供了两类不同的函数:- 无缓冲的输入输出函数:直接在存储器和文件之间传送数据,没有应用级缓冲。对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
- 通过调用
rio_readn和rio_writen函数,应用程序可以在存储器和文件之间直接传送数据。
#include "csapp.h"ssize_t rio_readn(int fd, void *usrbuf, size_t n);ssize_t rio_writen(int fd, void *usrbuf, size_t n);//若成功返回传送的字节数,若EOF则返回0,出错返回-1。
- 通过调用
- 带缓冲的输入函数:这些函数允许你高效的从文件中读取文本行和二进制数据。
- 一个文本行就是一个由换行符结尾的ASCII码字符序列。
- 一个包装函数(
rio_readlineb)从内部读缓冲区拷贝一个文本行,当缓冲区变空,会自动调用read重新填满缓冲区。
#include "csapp.h"void rio_readinitb(rio *rp, int fd);ssize_t rioreadlineb(rio_t *rp, void *usrbuf, size_t maxlen);
- 每打开一个描述符都会调用一次
rio_readinitb函数,它将描述符fd和地址rp处的一个类型为rio_t的读缓冲区联系起来。
5.读取文件元数据
文件的元数据是指文件的信息,通过调用stat和fstat函数实现。
#include#include int stat(const char *filename, struct stat *buf);int fstat(int fd, struct stat *buf);//若成功返回值为0,出错返回-1。
调用stat函数会把参数中提到的文件填写到stat数据结构中。
stat数据结构:
struct stat { mode_t st_mode; //文件对应的模式,文件,目录等 ino_t st_ino; //inode节点号 dev_t st_dev; //设备号码 dev_t st_rdev; //特殊设备号码 nlink_t st_nlink; //文件的连接数 uid_t st_uid; //文件所有者 gid_t st_gid; //文件所有者对应的组 off_t st_size; //普通文件,对应的文件字节数 time_t st_atime; //文件最后被访问的时间 time_t st_mtime; //文件内容最后被修改的时间 time_t st_ctime; //文件状态改变时间 blksize_t st_blksize; //文件内容对应的块大小 blkcnt_t st_blocks; //伟建内容对应的块数量}; 想要查看文件的某部分信息,直接按照数据结构的对应格式打印成员即可,如stat.ino_t。
6.共享文件
- 内核用三个相关的数据结构来表示打开的文件:
- 描述符表(descriptor table)每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。
- 文件表(file table) 打开文件的描述符表项指向问价表中的一个表项。所有的进程共享这张表。每个文件表的表项组成包括由当前的文件位置、引用计数(既当前指向该表项的描述符表项数),以及一个指向v-node表中对应表项的指针。关闭一个描述符会减少相应的文件表表项中的应用计数。内核不会删除这个文件表表项,直到它的引用计数为零。
- v-node表(v-node table)同文件表一样,所有的进程共享这张v-node表,每个表项包含stat结构中的大多数信息,包括st_mode和st_size成员。 看下图:
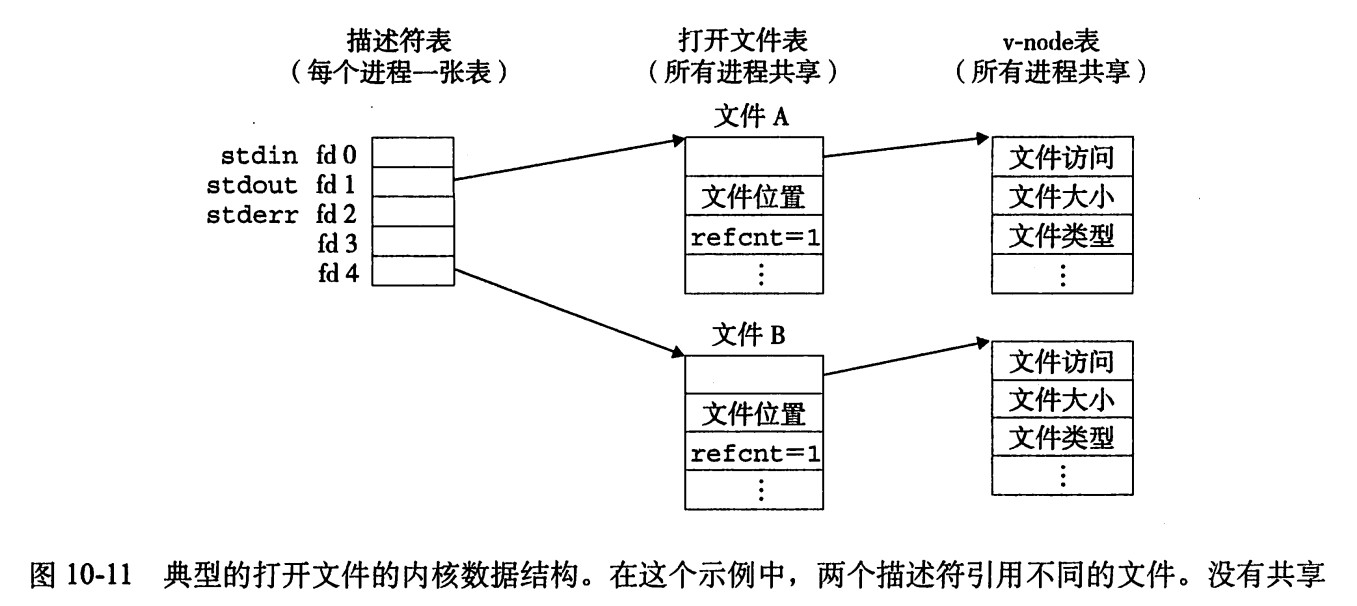
描述符1和4通过不同的打开文件表表项来引用两个不同的文件。这是典型的情况,没有共享文件,并且每个描述符对应一个不同的文件。
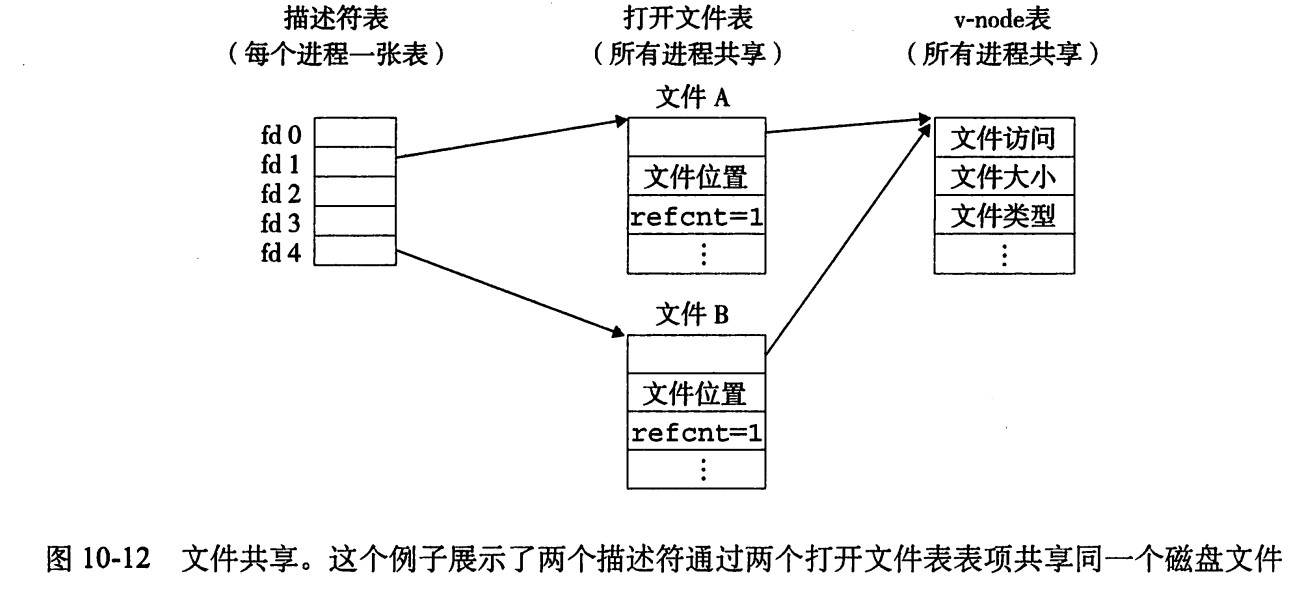
多个描述符也可以通过不同的文件表表项来应用同一个文件。如果同一个文件被open两次,就会发生上面的情况。关键思想是每个描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取数据。
父子进程也是可以共享文件的,在调用
fork()之前,父进程如第一张图,然后调用fork()之后,子进程有一个父进程描述符表的副本。父子进程共享相同的打开文件表集合,因此共享相同的文件位置。一个很重要的结果就是,在内核删除相应文件表表项之前,父子进程必须都关闭了他们的描述符。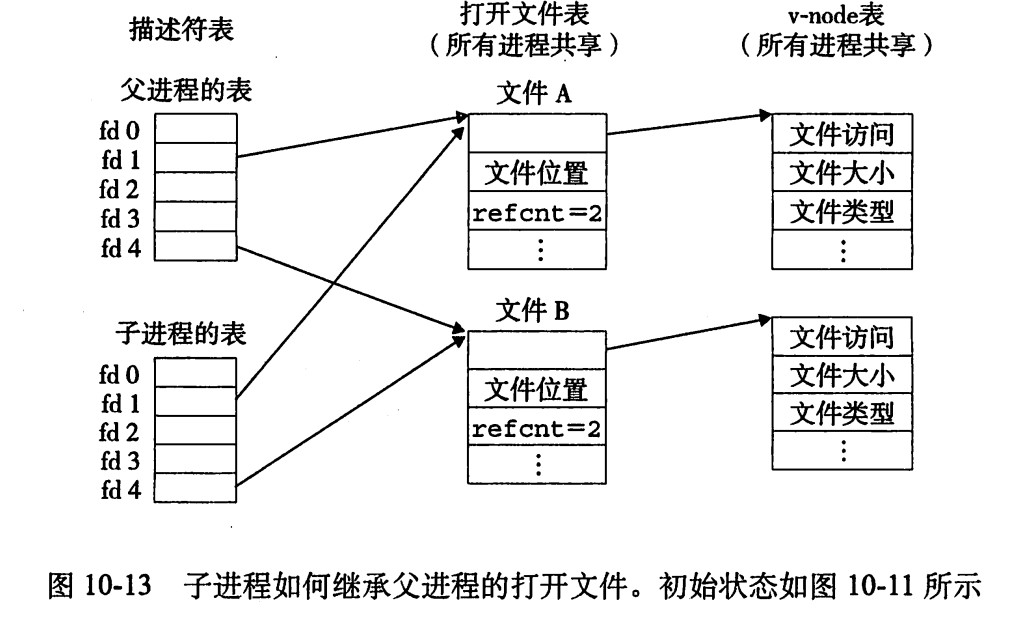
7. I/O重定向
重定向的一个标志就是 >。比如之前上课老师执行过的
who > user
其实就是外壳加载和执行完who程序,将应有的屏幕输出(或者可以理解为终端的printf)重定向到user这个文件中。
dup2函数 #includeint dup2(int oldfd, int newfd);
通过两个参数old和new应该也猜出来了,dup2函数将描述符表表项oldfd拷贝到newfd,覆盖描述newfd以前的内容,也就是说,如果newfd是之前打开过的描述符,那么newfd会被关闭,再执行oldfd到newfd的拷贝。
8.标准I/O
标准I/O库提供了Unix I/O的较高级别的替代。
标准I/O库将一个打开的文件模型化为一个流。对于一个程序而言,一个流就是一个指向FILE类型的结构的指针。- 类型为
FILE的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和RIO读缓冲区的一样:就是使开销较高的UNIX I/O系统调用的数量尽可能的小。 - 库中有打开和关闭文件的函数
fopen和fclose,读和写字节的函数fread和fwrite、读和写字符串的函数fgets和fputs,以及复杂格式化的I/O函数scanf和printf。
- 类型为
小结
Unix提供的系统级函数较少,应用程序在使用的时候反而会比较少的使用Unix I/O函数,而使用RIO包。标准I/O库就是在Unix I/O的基础上实现的,对于大多数应用程序而言,更简单,是优于Unix I/O的选择。然而,因为标准I/O和网络文件不兼容,在网络应用程序中会选择使用Unix I/O。
教材学习中的问题和解决过程
- 问题1:以前常用
FILE类型来打开、读写文件,学习了系统级I/O后,open和fopen的区别到底在哪里? - 问题1解决方案: 首先先了解两个文件系统:
- 缓冲文件系统
- 在内存开辟一个“缓冲区”,为程序中的每一个文件使用。
- 当执行读文件的操作时,从磁盘文件将数据先读入内存“缓冲区”,装满后再从内存“缓冲区”依此读入接收的变量。
- 执行写文件的操作时,先将数据写入内存“缓冲区”,待内存“缓冲区”装满后再写入文件。
- 非缓冲文件系统
- 缓冲文件系统是借助文件结构体指针来对文件进行管理,通过文件指针来对文件进行访问,既可以读写字符、字符串、格式化数据,也可以读写二进制数据。
- 非缓冲文件系统依赖于操作系统,通过操作系统的功能对文件进行读写,是系统级的输入输出,不设文件结构体指针,只能读写二进制文件,但效率高、速度快。
fopen是ANSIC标准中的C语言库函数,在不同的系统中应该调用不同的内核API,返回的是文件流,且是可移植的,fopen可以理解为封装的函数。open主要用来打开设备文件,linux系统函数还是open。fopen和open最主要的区别是fopen在用户态下就有了缓存,在进行read和write的时候减少了用户态和内核态的切换,而open则每次都需要进行内核态和用户态的切换;表现为,如果顺序访问文件,fopen系列的函数要比直接调用open系列快;如果随机访问文件open要比fopen快。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 195/195 | 1/1 | 10/10 | |
| 第三周 | 314/706 | 1/2 | 15/25 | |
| 第五周 | 254/960 | 2/4 | 10/35 | |
| 第七周 | 24/1759 | 2/6 | 15/50 | |
| 第九周 | 1207/2966 | 2/8 | 15/65 | |
| 第十一周 | 1207/2966 | 2/10 | 15/65 | |
| 第十三周 | 419/3385 | 3/13 | 16/81 | |
| 第十四周 | 104/3489 | 1/14 | 15/96 |
计划学习时间:12小时
实际学习时间:15小时